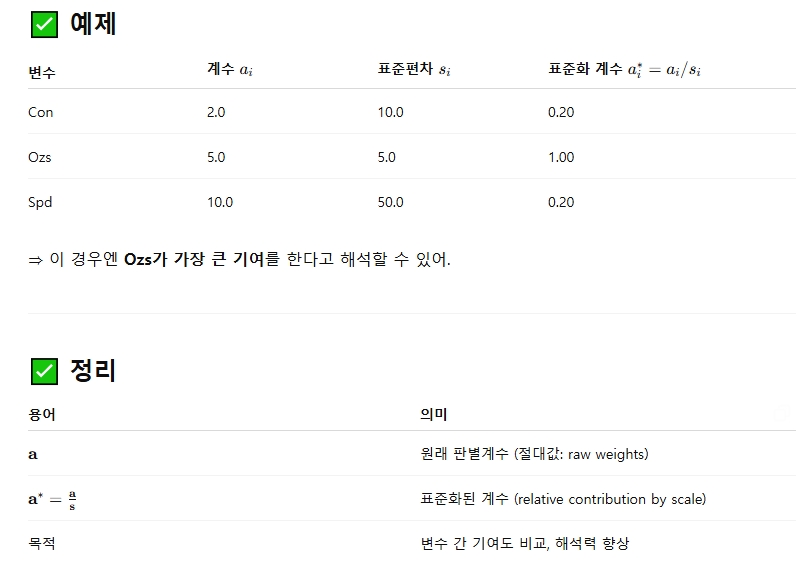
판별분석 6. 표준화된 변수의 판별분석


--------------------------------------------------------
# 2. 패키지 불러오기
library(readxl)
library(MASS)
library(ggplot2)
library(caret)
library(dplyr)
# 3. 데이터 불러오기
data <- read_excel("d:/mydata/QDA용.xlsx", sheet = "Sheet1")
# 4. 그룹 변수를 factor로 변환
data$그룹 <- as.factor(data$그룹)
# 5. 변수 선택 및 표준화 (z-score)
X_raw <- data[, c("Con", "Ozs", "Spd")]
X_scaled <- scale(X_raw) # 평균 0, 표준편차 1
y <- data$그룹
# 6. LDA 판별분석 수행 (표준화된 변수 사용)
lda_result <- lda(X_scaled, grouping = y)
# 7. 예측 수행
pred <- predict(lda_result, X_scaled)
# 8. 예측 결과 비교: 혼동행렬 및 정확도
conf_mat <- confusionMatrix(pred$class, y)
print(conf_mat)
# 9. 카이제곱 검정
chisq_result <- chisq.test(table(y, pred$class))
print(chisq_result)
# 10. 시각화용 데이터 정리
data$Predicted <- pred$class
df_plot <- data %>%
group_by(그룹, Predicted) %>%
summarise(n = n(), .groups = 'drop')
# 11. 막대 그래프
ggplot(df_plot, aes(x = 그룹, y = n, fill = Predicted)) +
geom_bar(stat = "identity", position = "dodge") +
labs(title = "실제 집단 vs 예측 집단 (표준화된 변수 사용)", x = "실제 그룹", y = "개수") +
theme_minimal()
# 12. 새로운 선수 예측을 위한 표준화
new_player_raw <- data.frame(Con = 65, Ozs = 40, Spd = 140)
# 기존 데이터와 동일한 방식으로 표준화 (동일 평균, 표준편차 사용)
new_player_scaled <- scale(new_player_raw, center = attr(X_scaled, "scaled:center"),
scale = attr(X_scaled, "scaled:scale"))
# 13. 예측
new_prediction <- predict(lda_result, new_player_scaled)
print(new_prediction)
cat("👉 새로운 선수의 예측 집단 (표준화된 LDA):", as.character(new_prediction$class), "\n")